 X
X
什么是算力?字面意思大家都懂,就是计算能力,也就是信息数据处理能力。
算力与人工智能之间则关系密切。人工智能的应用领域涵盖机器学习、深度学习、自然语言处理、计算机视觉等等,这些应用都需要处理大量的数据,进行复杂的数学运算和统计分析。 因此,高算力也就成为了人工智能应用的基础。
今天的人们都很熟悉AI了,毕竟人工智能的应用正在渗透入大众生活的方方面面。从自动驾驶技术的行人检测,再到语音识别和ChatGPT……AI要走入应用场景,就离不开底层的算力支持。
而这就对AI处理器提出了更高的技术要求。
虽然神经网络处理器(NPU)在性能、效率和算法灵活性方面已优于可编程的DSP(数字信号处理器),但这并不意味着 AI 处理中不需要 DSP。恰恰相反,对于许多应用的AI子系统来说,神经网络处理器(NPU)与矢量DSP是绝佳组合。
DSP在AI应用中发挥重要作用
从众多神经网络处理需求来看,例如卷积神经网络 (CNN) 或转换器,任何可以执行乘法运算并移动大量数据的处理器最终都可以执行这些计算密集型模型。借助先进的量化技术,经过训练的神经网络的32位浮点输出可以在8位整数控制器或处理器上运行,而且精度几乎没有降低。这意味着可以在 CPU、GPU、DSP 甚至MCU上处理CNN推理,准确度不受影响。
目前在电子行业内,通常用TOPS(每秒万亿次运算)来衡量AI处理器的性能,以这个数值来衡量“算力”。TOPS 的计算方式为:一个周期内可以完成的运算次数(一次乘积累加视为两次运算)x最大频率。这是很好的首次性能估算,因为大部分计算由对矩阵乘法的需求驱动,而矩阵乘法需要乘积累加运算。
按照这种计算方法,让我们来看下不同处理器类型的理想TOPS。
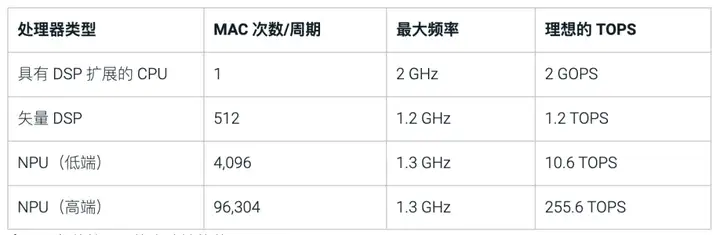
▲表1:各种处理器的大致性能范围
计算能力固然重要,但一些应用对实时性能的要求也很高。如在汽车应用中,当一辆汽车以70英里/小时的速度冲向行人,需要迅速决定是否要刹车。多摄像头配置、高分辨率、最低延迟,这些因素都对计算效率提出了更高要求,以帮助汽车做出生死攸关的决定。因此,我们需要更谨慎地选择用于处理AI推理的处理器。
GPU在AI计算中也可以提供高性能,但由于其功耗和面积成本很高,对于实时应用来说难以接受,所以并未在上表中列出。事实上,上表中所列的每种处理器都需要不同级别的功率和面积才能达到所需的运算能力。对于实时应用来说,功耗和面积(与成本和可制造性直接相关)几乎与性能同样重要。理论上来说,NPU经过设计和优化,是执行神经网络算法时性能、功耗和面积效率最高的处理器。
NPU 的最佳效率来自每个周期可以完成的大量乘积,以及一些专用于其他神经网络运算(例如激活函数)的硬件。NPU 面临的挑战是如何实现最大硬件加速,从而最大限度地提高神经网络效率,还要保持一定程度的可编程性。虽然现在全硬件神经网络ASIC比可编程 NPU更高效,但AI技术发展迅速,AI SoC的生产周期很长,因此保持一定程度的可编程性至关重要。
而且,NPU是专用的神经处理器引擎,只能执行AI计算。如果将矢量DSP和NPU结合使用,利用矢量DSP对NPU进行支持,就可以提供最高性能和额外的可编程性。例如,在自动驾驶汽车中,需要利用NPU来寻找行人、识别街道标志、使用神经网络进行雷达处理,在这些多应用处理中,系统可利用矢量DSP来为NPU进行额外筛选、雷达或LiDAR处理以及预处理和后处理。
NPU+DSP有三种配置方式,在下图中能看到在 AI 应用中将NPU和矢量DSP结合使用的各种可能性。在图中所示的三种情况下,高分辨率图像帧位于DDR内存中,等待在下一帧到达之前得到处理。
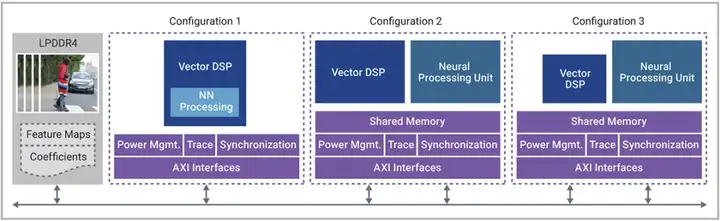
▲图1:矢量DSP和神经网络性能的不同组合
在第一种配置中(左侧),矢量 DSP本身既可用于DSP处理也可用于一部分AI处理,这属于运算能力低于1TOPS 的用例,这种配置需要大型DSP+小型AI。
在第二种配置中(中间),AI SoC 需要很高的矢量DSP性能和AI 性能,这种配置是大型 AI+大型 DSP。
第三个配置是小型 DSP+大型 AI。所有的处理都集中在神经网络上,虽然这些神经网络通常可以在 NPU 中执行,但有一些更复杂的神经网络模型需要矢量 DSP 的支持来执行浮点运算。
虽然市场上有多种矢量DSP和NPU供选择,但对于第二种和第三种配置,最好选择包含紧密集成处理器的 AI 解决方案。一些神经网络加速器将矢量DSP嵌入到神经网络解决方案中,这样限制了矢量DSP用于外部编程。
而新思科技的ARC EV7x 视觉处理器是异构处理器,它将矢量DSP与可选的神经网络引擎紧密耦合。为了提高客户的灵活性和可编程性,ARC EV7x系列正在发展成为 ARC VPX 矢量 DSP 系列和 ARC NPX NPU 系列。VPX 和 NPX 是紧密耦合的 AI 解决方案。图3显示了这两种处理器的粗略框图及其互连方式。
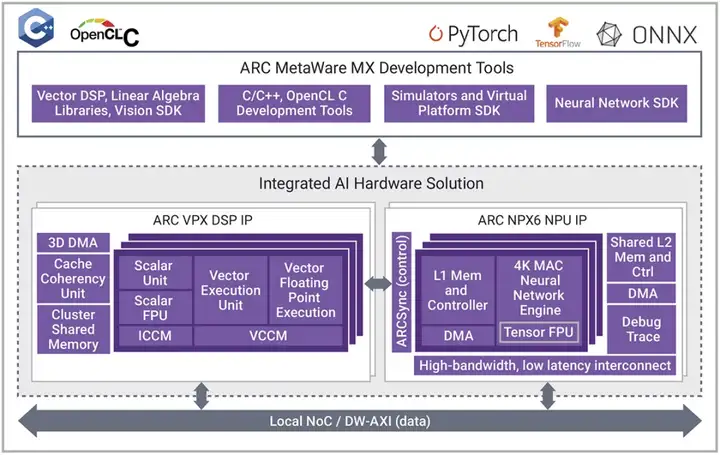
▲图2:新思科技 ARC VPX5 和 ARC NPX6 的紧密耦合型组合
随着嵌入式应用对AI处理的需求持续增长,要实现灵活设计,建议的最佳做法是结合使用 NPU 和矢量 DSP。前者用于AI处理,后者用于提供对NPU支持和DSP处理,这样有助于我们为快速发展的AI提供具有前瞻性的AI SoC,让支持人工智能的算力“算力全开”!
