 X
X
顾名思义呀,算力就是 computing power 的直译,其实就是计算性能的意思,是人工智能领域的三个基本要素之一,另外两个要素就是同样重要的算法(algorithm)以及数据(data)。这其中数据是基础,如果将算法看作是织布的方法,那么数据就是丝线,算力反映的就是织布机输出布匹面料的速度。
芯片的底层性能我们都会用诸如每秒执行多少次浮点操作、每秒执行多少条指令等说法,当然,反映到解决实际问题时,这样的性能指标是有点空泛的。
对于实际问题的性能表现,我们一般直接使用更直观的性能指标。例如游戏的话,就是每秒多少帧,如果是偏研发方向的话,可能会用每秒多少个像素,又或者它们的倒数,例如每帧多少个毫秒、每个像素多少纳秒等。
对于手机芯片,现在的手机 SoC 都属于 application processor(应用处理器),其中不仅包含了必不可少的 CPU、GPU,还有各种针对不同应用的处理单元,例如 ISP(图像信号处理器)、NPU(神经网络处理器)、视频编解码器等等。
在这几种单元中,发展最快或者说性能提升速度最快的就是 NPU。举个例子,联发科天玑 9000 里的 NPU——MediaTek APU 590,其性能效率是上一代的 4 倍,相对提升幅度比 CPU、GPU 提升大得多。
神经网络处理器,自然是用来跑神经网络,但是对很多人来说,神经网络这个词本身就比较神经——或多或少都听说过,但是这是个什么东西那是一脸懵逼的。
所谓神经网络,最初是人们在研究动物视觉系统后发现的一种信息处理方式。
人们通过在动物头上连接电极感应器,获知了动物在处理视觉信号的时候可以分为两种神经细胞,例如能对线条做出的简单神经元和能对线条运动作出反应的复杂神经元,这些神经元以网络的方式连接,于是人们将其归纳为一种数据处理结构,这就是神经网络。
在神经网络里,动物看到的东西首先是一堆像素点,然后会辨别出这其中有一大堆线条,之后是轮廓,最终就是辨别出眼睛里看到的到底是个什么东西,例如是花还是其他小动物。
对于我们人类和其他动物来说,这个辨别过程的复杂程度我们是很难察觉的,有句成语叫不假思索形容得很贴切,以至于我们会简单地以为我们看一眼就知道是啥,但是当我们试图用文字或者数学的方式将其完美地表达出来的时候,却会发现难度实在太高了。

例如阿拉伯数字 8,对我们人类来说,就是两个上下连接的圈圈,但是如果将这种认知变成计算机能识别手写数字 8 的代码时,却会发现会有各种混乱的情况需要处理,如果要对不同的手写数字字型以及混淆情况使用专门的代码来描述的话,在现实中将会成为非常棘手的事情(在人工智能中这样的方式类似于专家系统)。
神经网络则是采用了另一种方式,那就是给它喂一大堆手写体数字,这些数据被称为训练样本,之后,我们开发出一个可以从这些训练样本中进行学习的系统,从而实现自动推断识别这些手写数字或者其他类型数据(例如照片、语音、运动行为等)的规则。
类似的例子我们可以举出非常多,例如使用手机或者中画幅相机拍摄照片,从传感器获得的 raw 生图数据可能有多达 14-bit 甚至 16-bit 的数据,这些生图数据可以透过不同的去马赛克算法还原成一张动态范围非常高的图片。
此时就需要对其进行 tone mapping 处理,确保可以在低动态范围的显示器上正确显示。完成 Tone Mapping 后画面可能会出现局部过曝、欠曝的情况,此时就需要进行 HDR 亮度处理。处理涉及到场景识别,毕竟不同的场景明暗影调都是不一样的,人工智能此时可以帮助大家进行快速的处理,提供一张能呈现高动态范围而且影调、色彩都恰到好处的图片。
这不是一件容易的事情。
以上面那堆用于训练手写体识别的训练样本为例,它相当于一个二维矩阵,纵向有 10 行,横向有 16列,假设每个字的框框是 32×32 个像素,那么这里的像素样本数量是 10*16*32^2=163,840 个,涉及的运算量非常高。
现在的图像识别神经网络大都采用名为 CNN 或者说卷积神经网络的方式进行计算,它的原理是用一个名为卷积核的参考矩阵和训练样本的形式进行 MAC(Multiply Accumulate,乘积累加,也就是 x*w+b 的形式,其中有一个乘积运算和一个加法运算)指令运算,得出一个输出矩阵——特征图。
我们可以取一个更直观的比喻。
相信大家都用过卷纸,最常见的卷纸里都有一个圆的纸轴,你可以将其是作为卷积运算里的卷积核,卷纸围绕着纸轴缠绕,而卷积计算就相当于把记录在纸轴上的数据与缠绕的卷纸上的数据进行 MAC 计算。
这里需要注意的是,由于每卷一圈卷纸的周长都会大一些,如果卷纸上的数据记录占用的位置是等距的,那么每圈卷纸和纸轴对应的数据位置都会有一定的出入,这也正是卷积计算的重要特征。
每圈卷纸计算出来的数据放置到一个新的数据矩阵中,周而复始直到卷纸缠绕完,这一整条卷纸算是完成一次卷积运算,同时一个新的数据矩阵(特征图)也得出了。
基本上这就是卷积计算的基本概念,在神经网络计算中它的目的是用数学的办法提取出图像的特征。
例如,如果我们要判定某个图片(TS)里是否包含 \ 的图案(例子参考自李永乐老师的视频),可以先人为地选定一个包含类似 \ 图案的 3*3 的卷积核(K)来对图案进行计算:
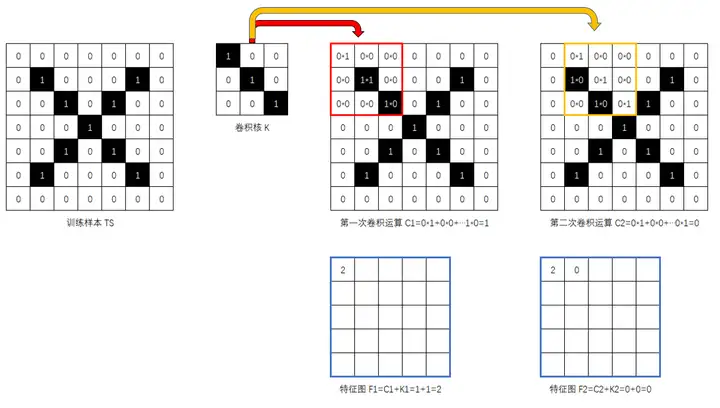
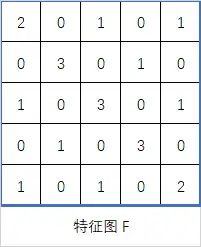
上图就是对一个我们认为是一个交叉或者字母 X 的图案和 3*3 卷积核进行卷积运算后得出的特征图,其中数值为 3 的位置可以视作高度符合包含 \ 的位置,数值为 2 表示这个位置接近 \,0 和 1 则表示这里和 \ 没啥相似的地方。
由于特征图有点大,所以我们还会进行池化获得激活值,将特征图简化并重新得出一个新的特征矩阵,这个过程也会涉及一些简单的运算。
但是一次卷积可能还有一些混淆是不能完全解决的,所以可能还会进行多次(层)卷积,最终得出更多的特征图,在现实世界中随着问题的复杂性提高、卷积核的数量也会提高,随之而来的是生成的特征图也更多。
从整体来看,CNN 里最常见的运算指令无疑是 MAC 指令(与卷积核相乘,获得结果后再与卷积核相加获得特征图,所以是 x*w+b),所以对于 CNN 来说,处理器的 MAC 指令吞吐率可以在很大程度上反映了该处理器的人工智能计算性能,然后就是访存性能以及内存大小,这些因素最终决定了处理器执行神经网络或者说人工智能计算时的性能。
前面使用手写体识别时我们是以是一个较低分辨率的图片来举例,那么如果是要对 4K图片处理的话所需要的实际计算量会是如何呢?以一张分辨率为 3840×2160 的 RGB 图片和 3*3 卷积核为例,第一层卷积计算所需要的 MAC 指令大约是:
3^2 * (3840*2160 * 3) = 223,948,800 条 MAC 指令
需要注意的是,如果是视频的话,就需要考虑时间约束问题,例如 30 fps 的视频,就需要 223,948,800 * 30 fps = 6,718,464,000 MAC/秒,或者说起码得 6.7GIPS。随着卷积层数的增加和网络复杂性的变化,具体的算力需求可能会呈指数级上升,而深度学习的特征之一正是因为多层卷积计算。
很显然,CNN 可以有多种实现形式,现在最常见的就是 ResNet、Inception 等,在测试软件 AI-benchmark 中的子项目你可以看到它们的身影,它们的首要目标大都是试图获得尽可能高的准确性。
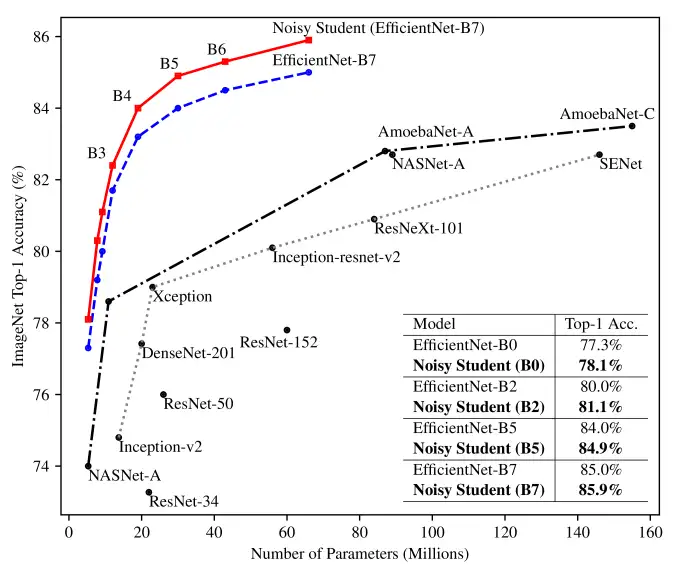
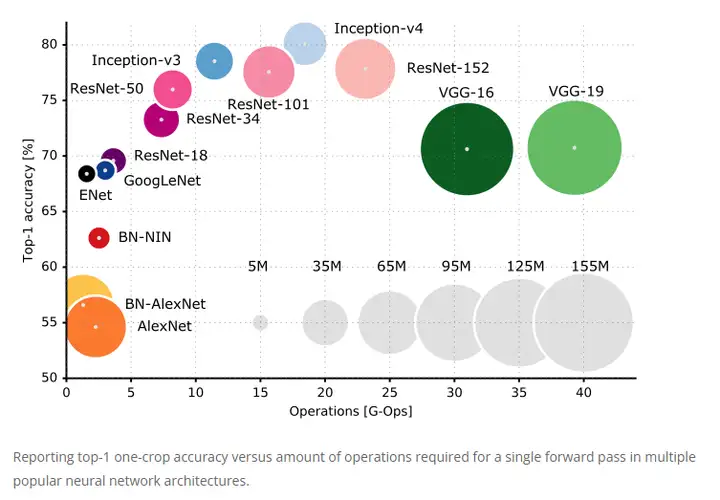
2012 年被视作第三波人工智能崛起的年份,AlexNet 凭借比第二名低 10.8% 的 Top5错误率拿下了 ImageNet 大规模视觉识别挑战赛的第一名,AlexNet 需要极高的计算性能,但是由于 GPU 和 CUDA 的出现使得这一切成为了可行。
自此以后,人工智能计算出现了前所未有的突飞猛进,以顶尖人工智能系统的性能为例,在 2012 年到 2019 年间,顶尖人工智能系统的性能以每年 10 倍的速度提升,相当于同期 GPU 性能提升速度的 35 倍。
即便如此,神经网络计算所需的庞大计算量依然是通用芯片难以满足的(见上图),强大的性能需求推动了神经网络芯片技术的发展,谷歌 TPU 就是首款大规模应用的 AI 专用加速器,之后 NVIDIA 也在其 Volta GPU 里引入了 Tensor Core 进一步稳固其 AI 市场领域的龙头位置。
如今,AI 加速器已经遍地开花,例如 AMD 在其 CDNA2架构 GPU 里引入 Matrix Core、Intel 在 Xe HPC/HPG GPU 中引入 Matrix Engine,专用 AI 加速器更是举不胜举。
回到现在大家比较关心的手机设备,对手机或者其他终端设备来说,在使用神经网络做 AI 应用的时候,通常都是属于推理。
从高层次角度来看的话,深度神经网络的使用是一个两阶段(训练和推理)的过程:
首先训练一个神经网络,神经网络会对输入的训练样本进行计算,获得一份权重表,然后用这个权重表猜测我们给定的一个测试样本,如果猜测结果是错误的,那就重新调整权重高低,直到猜测正确为止。
神经网络训练需要消耗非常高的资源,按照前百度首席科学家吴恩达的说法,训练一个百度汉语语音识别模型不仅需要 4TB 的训练数据,而且还需要多达 20 ExaFLOPs(百亿亿次浮点操作)的算力,远远超出目前以及可见将来的任何一部智能手机本地算力水平,因此训练计算一般都是在超级计算机上进行。
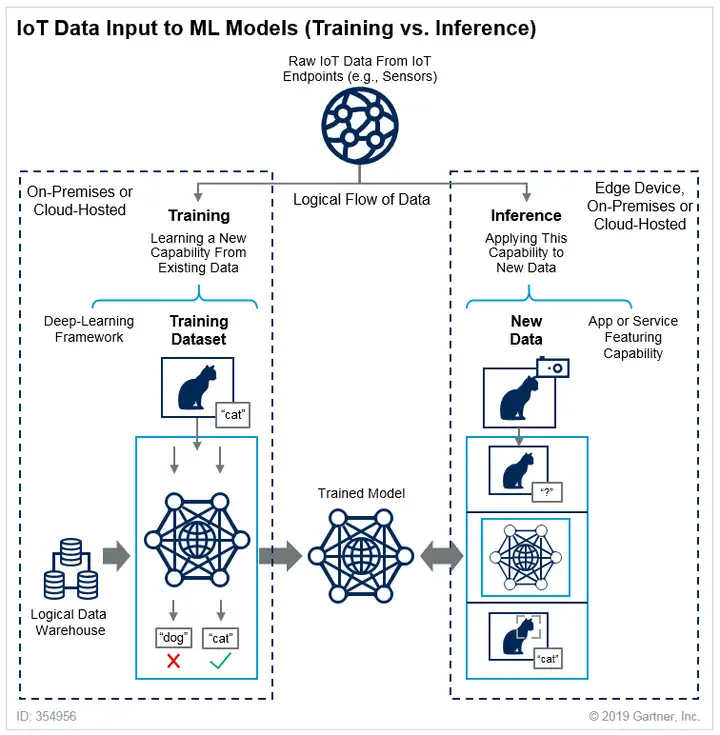
经过训练后的神经网络可以用于猜测其他未标记的测试对象,这时候就进入了推理阶段,也是终端设备在人工智能上的最主要应用方式,此时使用的神经网络虽然是经过训练的,但是其个头会小很多,因为一些低权重由于对结果没有实质影响而被抛弃(这一步被称作模型量化)。
此外,推理运算所需的数据精度需求也会大为降低,从训练神经 网络的 FP32/FP16 量化为 INT8 即可,虽然运算精度下降,但是对推理结果的准确度影响也就是 1% 以内,随之而来的则是内存占用显著降低以及性能获得显著提升。
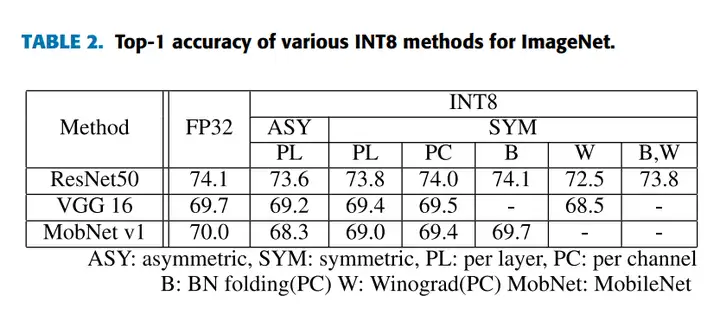
上图是 2021 年韩国首尔大学 SUMIN KIM 等人对移动 GPU 以 INT8 量化推理性能评估论文(10.1109/ACCESS.2021.3133100)中提供的 FP32 和 INT8 准确性比较,可以看到在推理的时候,INT8 的准确性和 FP32 相差非常小。
由于直接使用 INT8 量化在推理运算方面的精度损失非常低,因此目前绝大部分的 AI 硬件加速器都提供了 INT8 支持,在开发工具方面,像目前的深度学习库 TensorFlow、PyTorc、MXNet、OpenVINO、TensorRT 都提供了 int8 的支持,所以 INT8 现在已经成为了推理方面最常见的精度格式。
除了 INT8 外,目前 INT4 也开始渐露头角,例如 2018 年 NVIDIA 图灵架构里第二代 Tensor core 就提供了 INT4 支持,但是和 INT8 相比 INT4 量化目前看来需要一些特殊的手段才能实现较低的准确度损失,这对于某些应用特别是强调安全性的汽车自动驾驶来说 INT4 仍然是存疑的,因此你目前看到的汽车自动驾驶推理计算主要采用 INT8 量化。
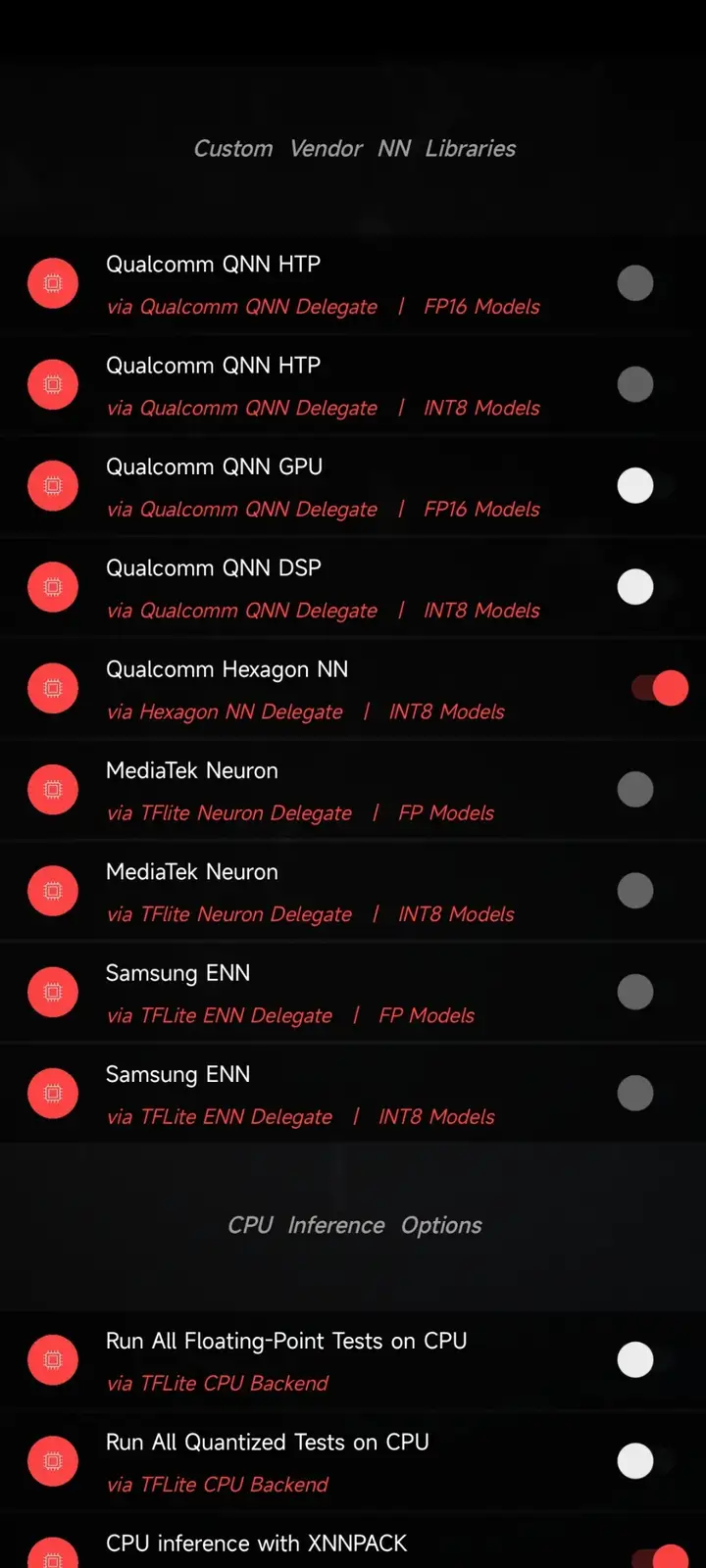
上图是 AI-Benchmark v5 的加速模式设置选择界面,手机为 K40,图中的设定是 AI-Benchmark v5 的默认设置,可以看到此时 AI-Benchmark v5 选择的 AI 加速精度为 INT8。

上图是另一部手机——Find X5 Pro 天玑 9000 版的默认 AI 加速设置,可以看出这里同时提供了 FP 和 INT8 的支持。
根据我的观察,目前已知的手机 AI 性能测试工具,基本上都是测试神经网络推理性能,而且都提供了 INT8 支持,至于更低精度的 INT4 目前还没看到,NVIDIA 给 http://mlcommons.org 递交过一个针对 INT4 修改的 MLPerf 0.5 推理测试,但是手机版尚未看到。
换句话说,目前当我们讨论手机 AI 性能的时候,一般默认指的是 INT8 推理性能,这也是业界普遍的认知。
例如,在去年底国内手机厂商还纷纷推出了各自的手机 AI 加速芯片,这其中以 OPPO 的 MariSilicon X 最为亮眼。

按照 OPPO 的资料,这枚 MariSilicon X 集成了一枚 INT8 性能高达 18 TOPS 的神经网络处理单元,其中用低明度得到小字体标注了等效 INT4 性能为 72 TOPS。
这里为什么会特别提及 INT4 呢?正如前面我们提到过 INT4 是需要特别场合才能使用的,类似 MariSilicon X 这种属于 Pre-ISP 场合,对精度的需求顾虑不像汽车自动驾驶那样有安全先决的因素,因此 INT4 也是有机会在手机推理计算上得到应用。
按照 Andres Rodriguez 编写的《Deep Learning Systems Algorithms, Compilers, and Processors for Large-Scale Production(针对大尺度生产的深度学习系统算法、编译器以及处理器)》一书中,就列出了不同精度格式的应用场景:

其中提到的边缘设备就包括手机设备,在个别场合里可以使用 INT4,个别场合就是指对准确度和安全性要求相对较低的情况,毕竟 INT4 在有符号的情况下所能提供的正数数值范围只有 0 到 7、负数范围是 -7 到 -1,无符号时的正数范围是 0 到 15,其数值范围相当有限,当卷积核有负值或者之后归一化的时候,INT4 就会捉襟见肘。
在同一本书中提供了不同精度在 45 纳米制程下各种运算形式和访存操作的耗电、芯片面积(数据源自 NVIDIA 首席科学家 Bill Dally 2017 年的资料),可以看到 8-bit 加法和 8-bit 乘法消耗的电力分别是 fp32 的 3% 和 5%,面积则分别是 0.86% 和 3.7%。
由此可见,8-bit 计算在耗电和芯片成本上远比 FP32 低很多,已经达到了数量级的差别,结合我们前面提到 INT8 在推理计算方面具有和 FP32 相当的准确度,因此 INT8 自然而然成为非常重要的深度学习推理运算数据格式以及性能指标,意义比 INT4 更高(故此 OPPO 的 Marisilicon X 在提及 INT4 等效性能时字体特意采用了低明度的小字体)。
 0
0Marisilicon X 负责前端 ISP(RAW 域)处理,能实现出色的 HDR、降噪效果
人工智能和图像处理结合是目前乃至未来手机芯片领域发展最快的应用领域,除了我们上面提及的 OPPO MariSilicon X 外,各个手机厂商也都推出各自的 ISP,像 Vivo 的 V1、小米的澎湃 C1、华为海思越影以及荣耀 Magic 4 里的 AI ISP。
其中前两者目前的公开资料都并未提及算力是多少,也并未明确是否具备人工智能加速。而海思越影和荣耀的 AI ISP 则是明确表示是具备人工智能加速的,特别是荣耀的 AI ISP 有明确的 28 TOPS 算力指标,但是并未说明到底是 INT8 还是 INT4。
考虑到我们前面提到的 INT8 和 INT4 在可用性上存在一定区别,因此在荣耀在明确指标数据格式之前我觉得不适合和 MariSilicon 的 INT8 18 TOPS、INT4 72 TOPS 直接对比,因为如果荣耀的指标是 INT4 下的话,那对应 MariSiliton 算力指标就是 72 TOPS 了。
最后,芯片算力只是人工神经网络三个要素之一,另外的两个要素——算法和数据也是同样重要不可或缺的,反映到像手机计算拍摄方面,则是意味着厂商需要长时间在影像科学上的积累才能获得足够的算法开发和训练样本,只有这样才能让像 MariSilicon X 等芯片充分发挥其强大的 RAW 端算力,使得大家看到“亮的够亮、暗的够暗”的画面。
芯片开发充满了对算力、耗电、成本以及应用灵活性等问题的挑战和妥协,特别是高端芯片,其研发成本之高和周期之短是常人难以想象的,对于芯片设计团队来说是只许成功不许失败的独木桥,国内厂商近年来对芯片研发大力加码,使得我们看到了越来越多高端芯片的出现,希望它们中的大多数都能取得成功,并且在更多的领域得到落地应用,让研发费用得到有效摊平,进入正向良性循环,实现更多高端的芯片突破。
